Here is a rather vanilla fast table load destination using SSIS data flow task. Notice how I have Rows per batch=200,000 and Maximum insert commit size=200,000. You might expect that the fast load will insert about 200,000 rows per batch and transaction. You would be wrong, as it is also gated by the buffer size of the data flow task. To determine how many rows are being inserted per batch/transaction, simply use SQL Profiler and trace the INSERT BULK commands. They are simply SQL:BatchCompleted events. To see the number of rows, look at the RowCounts column in the trace. It will probably be a little less than 10,000.
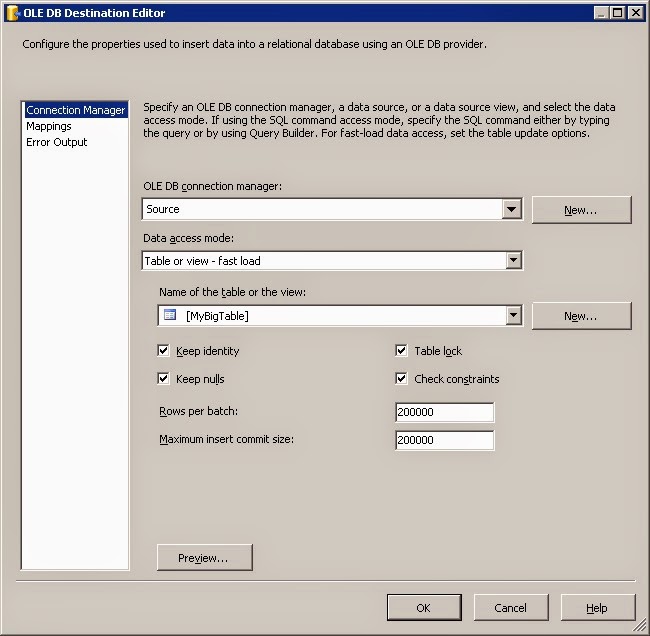
Firstly why is 10,000 rows per commit slow? If you have no indexes on your large table, the chances are that the loading is very fast. However, if there are non clustered indexes, the loading is slowed down by sorting the batch records into each index sequence and applying them to the indexes. Applying the keys to the index could touch up to 10,000 pages. Then the updates are committed, requiring writing out to disk all updates. Increasing the commit size can make updating indexes more efficient. Note, the performance does not get forever faster as the commit size increases. There is a memory cost with the large commit sizes and sorting larger groups of records increases at a greater then linear rate. To determine the best size for your task, run and monitor several sizes and plot their speeds. Choose the buffer size (batch/commit size) that maximizes load speed. Note, the optimal speed for a small table, will not be the same once the table becomes very large with indexes larger than db cache memory.
Also note, if you are loading a table from scratch, it can be more efficient to load the table with just a clustered index, then create the indexes in parallel after loading. Of course, partitioned tables will give you more flexibility in tuning your index build and loading.
Anyway, to increase the commit size, you will need to increase the Data Flow buffer size. See below, the DefaultBufferMaxRows is 10,000 and DefaultBufferSize is 10,485,760 bytes. Increasing these configuration settings to get larger commits.


No comments:
Post a Comment